LM Studio 0.3.14: 多 GPU 控制 🎛️

LM Studio 0.3.14 为拥有 2 个或更多 GPU 的配置带来了新控件
LM Studio 0.3.14 引入了针对多 GPU 配置的全新精细控制功能。新功能包括:启用/禁用特定 GPU 的能力、选择分配策略(平均分配、优先顺序),以及将模型权重限制在专用 GPU 内存中。
通过应用内更新,或从 https://lm-studio.cn/download 升级。
GPU 贵族 🎩
如果您的系统中有超过 1 个 GPU,您可能不再被视为“GPU 贫困户”。但能力越大,责任越大。您需要明智地管理您的 GPU,以从中获得最佳性能。
在 LM Studio 0.3.14 中,我们引入了新的控件,以帮助您更好、更有目的地管理 GPU 资源。其中一些新功能目前仅适用于 NVIDIA GPU。我们正在积极努力,争取也为 AMD GPU 提供这些功能。
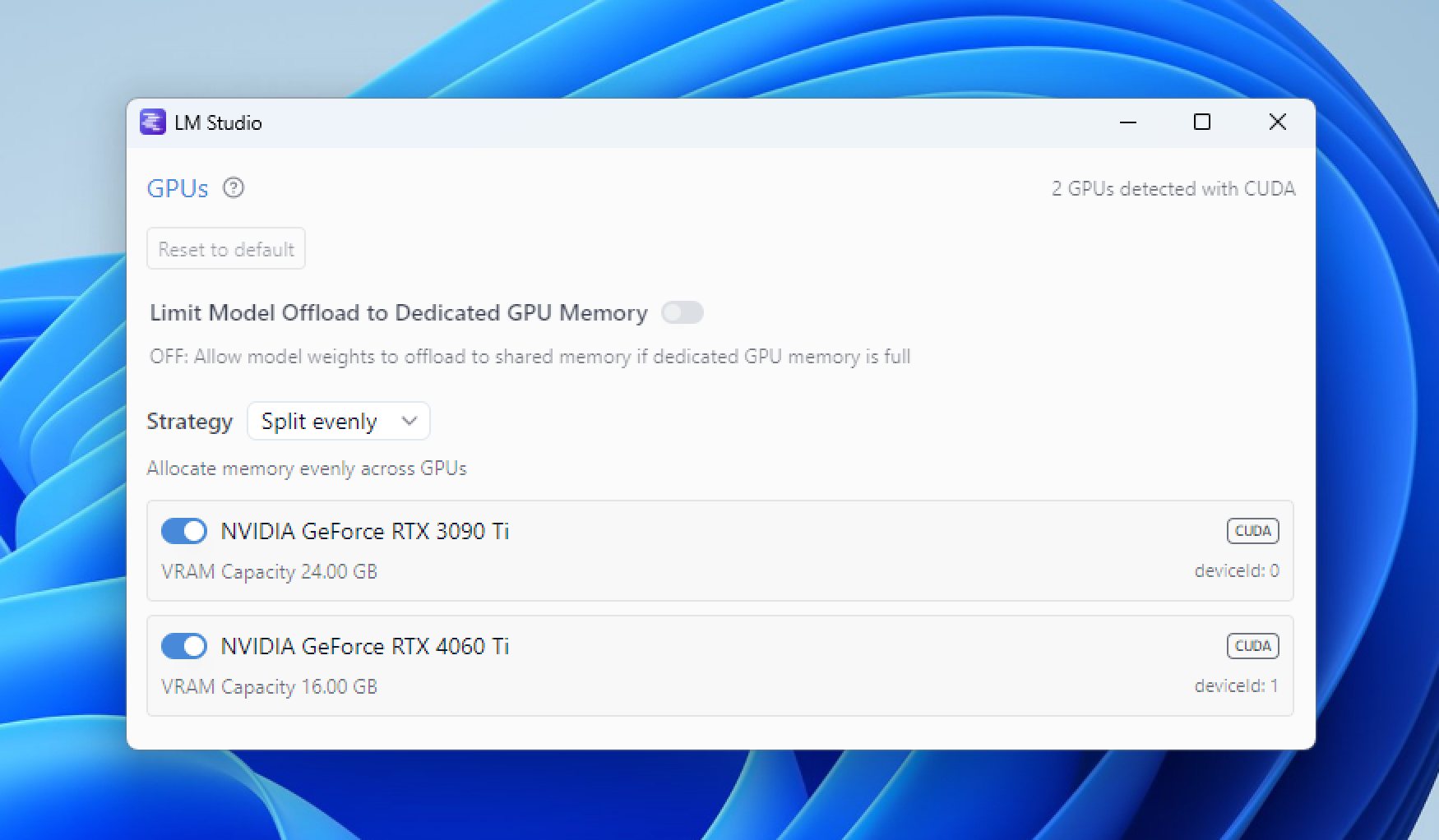
多 GPU 控制
使用 Ctrl+Shift+Alt+H 在新窗口中弹出它们。
要打开 GPU 控制,请在 Windows 或 Linux 上按 Ctrl+Shift+H,在 Mac 上按 Cmd+Shift+H。您也可以通过按 Ctrl+Alt+Shift+H/Cmd+Option+Shift+H 在弹出的新窗口中打开 GPU 控制。
随着我们对最佳配置了解更多,我们将致力于在手动控制之外添加自动模式。这些功能可通过 LM Studio 的图形用户界面 (GUI) 使用,未来也将通过 lms 命令行界面 (CLI) 提供。
启用或禁用特定 GPU
使用每个 GPU 旁边的开关来启用或禁用它。禁用 GPU 意味着 LM Studio 将不会使用它。如果您拥有强大和不那么强大的 GPU 混合配置,或者您想为其他任务保留一个 GPU,这会很有用。
该视频演示了禁用 GPU 1 然后加载模型的过程。模型仅加载到 GPU 0 上,GPU 1 上没有任何活动。
禁用 GPU 1 并仅在 GPU 0 上加载模型
将模型卸载限制到专用 GPU 内存
目前仅支持 CUDA
LLM(大型语言模型)可能是内存密集型的。通常占用最多内存的组件是模型权重和会话上下文缓冲区。在模型权重过大无法完全放入单个 GPU 的专用内存的情况下,您的操作系统可能会在共享 GPU 内存中分配内存。这会大大降低运行速度。
视频首先展示了此选项关闭时的状态,此时内存被分配到专用内存和共享内存。然后,该选项被打开,模型仅加载到专用内存中。
将模型卸载限制到专用 GPU 内存
模型权重位于专用 GPU 内存中
“将模型卸载限制到专用 GPU 内存”模式确保模型权重仅加载到专用 GPU 内存中。如果模型权重过大无法完全放入专用 GPU 内存,LM Studio 将自动减少 GPU 卸载大小,以使模型权重适合专用 GPU 内存,其余部分则放入系统 RAM。
根据我们的测试,将模型权重分割到专用 GPU 内存和系统 RAM 中,比使用共享 GPU 内存要快。如果您的体验有所不同,请告诉我们!
上下文可能会分配在共享 GPU 内存中
上下文缓冲区可能仍然使用共享内存。假设模型的权重可以放入专用 GPU 内存并留有一些空闲空间。模型将全速运行,直到上下文增长超出剩余的专用内存。随着上下文溢出到共享内存,性能将逐渐降低。这种方法可以实现快速的初始性能,而不是将所有上下文都限制在较慢的 RAM 中。
优先顺序模式
目前仅支持 CUDA
您现在可以设置 GPU 的优先级顺序。这实际上意味着什么
- 如果您有多个 GPU,您可以设置 LM Studio 尝试将模型分配到 GPU 的顺序。
- 系统将首先尝试在列表中靠前的 GPU 上分配更多资源。一旦第一个 GPU 满载,它将转移到列表中的下一个,依此类推。
该视频演示了加载多个模型的过程。请注意 LM Studio 如何在将资源分配到 GPU 1 之前,首先完全填充 GPU 0。
按顺序填充模式:按照您指定的 GPU 优先顺序分配模型
拥有 3 个或更多 GPU 的配置?我们期待您的反馈!
我们正在寻找用户,他们可以帮助我们测试并提供关于新功能在此类配置下如何运作的反馈。如果您拥有 3 个或更多 GPU 的配置(Windows 或 Linux),我们非常希望您能通过 [email protected] 联系我们。谢谢!
0.3.14 - 完整发布说明
**Build 1** - New: GPU Controls 🎛️ - On multi-GPU setups, customize how models are offloaded onto your GPUs - Enable/disable individual GPUs - CUDA-specific features: - "Priority order" mode: The system will try to allocate more on GPUs listed first - "Limit Model Offload to Dedicated GPU memory" mode: The system will limit offload of model weights to dedicated GPU memory and RAM only. Context may still use shared memory - How to open GPU controls: - Windows: `Ctrl+Shift+H` - Mac: `Cmd+Shift+H` - How to open GPU controls in a pop-out window: - Windows: `Ctrl+Alt+Shift+H` - Mac: `Cmd+Option+Shift+H` - Benefit: Manage GPU settings while models are loading - LG AI EXAONE Deep reasoning model support - Improved model loader UI in small window sizes - Improve Llama model family tool call reliability through LM Studio SDK and OpenAI compatible streaming API - [SDK] Added support for GBNF grammar when using structured generation - [SDK/RESTful API] Added support for specifying presets - Fixed a bug where sometimes the last couple fragments of a prediction are lost **Build 2** - Optimized "Limit Model Offload to Dedicated GPU memory" mode in long context situations on single GPU setups - Speculative decoding draft model now respects GPU controls - [CUDA] Fixed a bug where model would crash with message "Invalid device index" - [Windows ARM] Fixed chat with document sometimes not working **Build 3** - [Advanced GPU controls] Fixed a bug where intermediate buffers were being allocated on disabled GPUs - Fixed "OpenSquareBracket !== CloseStatement" bug with Nemotron model - Fixed a bug where Nemotron GGUF model metadata was not being read properly - [Windows] Fixed: Make sure the LM Studio.exe executable is also signed. Should help with anti-virus false positives **Build 4** - [Advanced GPU controls] Allow disabling all GPUs with any engine - [Advanced GPU controls] Fix bug where disabling a GPU would cause incorrect offloading when > 2 gpus - [Advanced GPU controls][CUDA] Improved stability of"Limit Model Offload to Dedicated GPU memory" mode - Added GPU controls logging to "Developer Logs" - Fixed a bug where sometimes editing model config inside the model loader popover does not take effect - Fixed a bug related to renaming state focus on chat cells **Build 5** - [Advanced GPU controls] Enlarge GPU controls pop-out window
更多内容
- 下载最新版 LM Studio 应用程序,支持 macOS、Windows 或 Linux。
- 如果您希望在您的组织或工作中使用 LM Studio,请联系我们:LM Studio 商业应用
- 如需讨论和社区支持,请加入我们的 Discord 服务器。
- LM Studio 新用户?请查阅文档:文档:LM Studio 入门指南。