在 LM Studio 中引入统一的多模态 MLX 引擎架构

LM Studio 的 MLX 引擎 (MIT) 利用两个强大的 Python 包,可在 Apple Silicon M 芯片上高效运行 LLM:用于文本生成的 mlx-lm(作者:@awni、@angeloskath、Apple),以及用于视觉语言模型的 mlx-vlm(作者:@Blaizzy)。
从 mlx-engine commit f98317e(应用内引擎 v0.17.0 及更高版本)开始,我们迁移到一个新的统一架构,该架构整合了这些包的底层组件。现在,mlx-lm 的文本模型实现始终被使用,而 mlx-vlm 的视觉模型实现则被模块化地用作“附加组件”,以生成可被文本模型理解的图像嵌入。
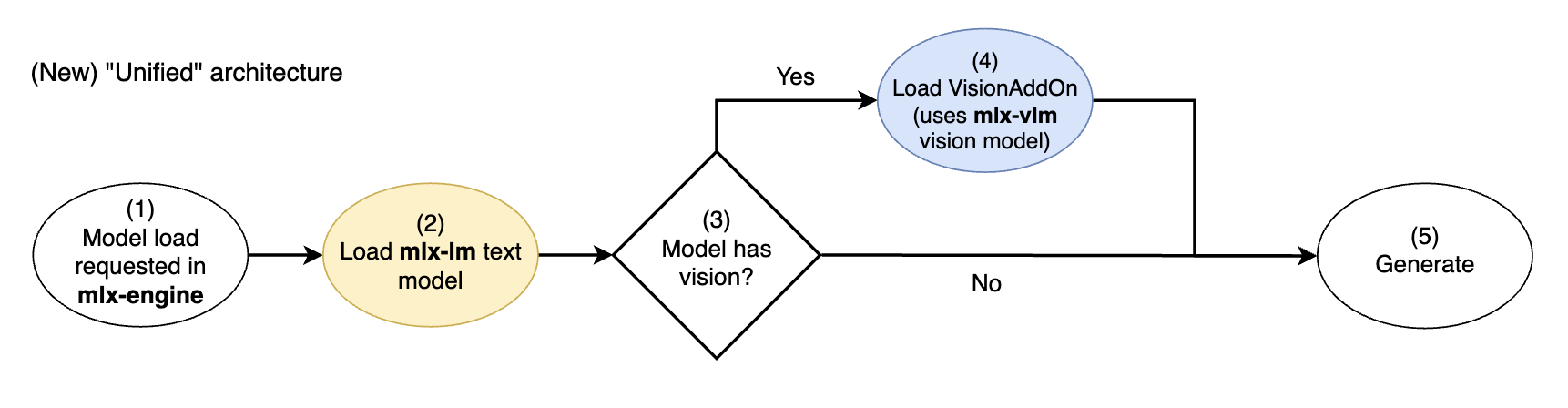
新的 mlx-engine 统一视觉模型架构。mlx-lm 文本模型通过 mlx-vlm 视觉附加组件进行扩展
这极大地提升了使用多模态 MLX VLM(例如,Google 的 Gemma 3)时的性能和用户体验。例如,与 VLM 进行纯文本聊天现在可以受益于提示缓存——这曾是纯文本 LLM 独有的功能——从而大大加快后续响应速度。这使得 MLX VLM 在文本任务上可以与纯文本 LLM 无缝互换,同时还提供了视觉能力作为额外优势。
👓 继续阅读,深入了解 LM Studio MLX 引擎中如何实现这一统一架构的问题、解决方案和方法。
👷 欢迎为 LM Studio 的 MLX 引擎进行开源贡献!如果您想帮助我们将统一架构扩展到更多模型,请参阅此 GitHub Issue,这是一个很好的起点。
什么是多模态模型?
多模态 LLM 是一种可以接收多种模态输入的 LLM。这意味着除了能够处理文本输入外,LLM 还可以接受图像和/或音频输入。
新的 MLX 引擎尚不支持音频处理,但我们计划将此方法也应用于音频输入。
通常,具备视觉能力的 LLM 通过以下流程摄取图像输入
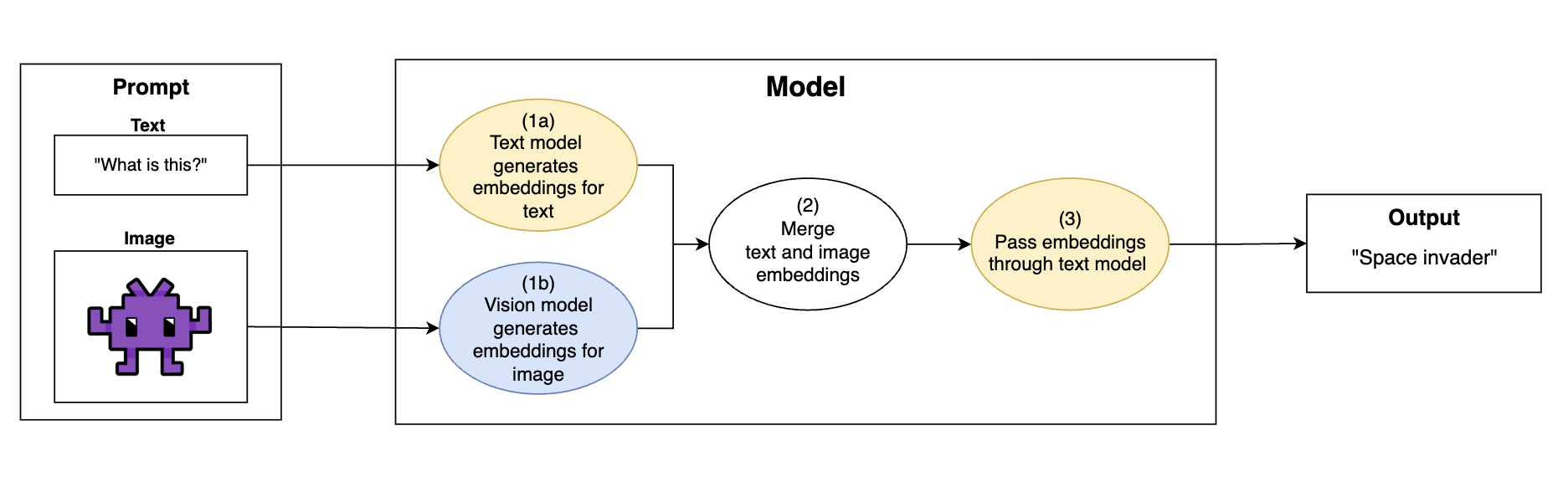
多模态视觉 LLM 的通用操作流程:将图像转换为文本模型可理解的嵌入,然后使用文本模型生成输出
- 提示(Prompt)携带文本和图像输入
- (1a) 模型的“文本”部分将文本编码为模型的嵌入空间
“这是什么?”→[0.83, 0.40, 0.67, ...]
- (1b) 模型的“视觉”部分将图像编码为文本模型的嵌入空间。这将图像转换为文本模型可以理解的格式
image.png→[0.28, 0.11, 0.96, ...]
- (2) 文本和图像嵌入合并
[0.83, 0.40, 0.67, ...]+[0.28, 0.11, 0.96, ...]→[0.83, 0.40, 0.67, ..., 0.28, 0.11, 0.96, ...]
- (3) 合并后的嵌入通过文本模型,模型根据文本和图像中的信息生成文本
如果提示中没有图像,则“合并后的嵌入”仅为文本嵌入。
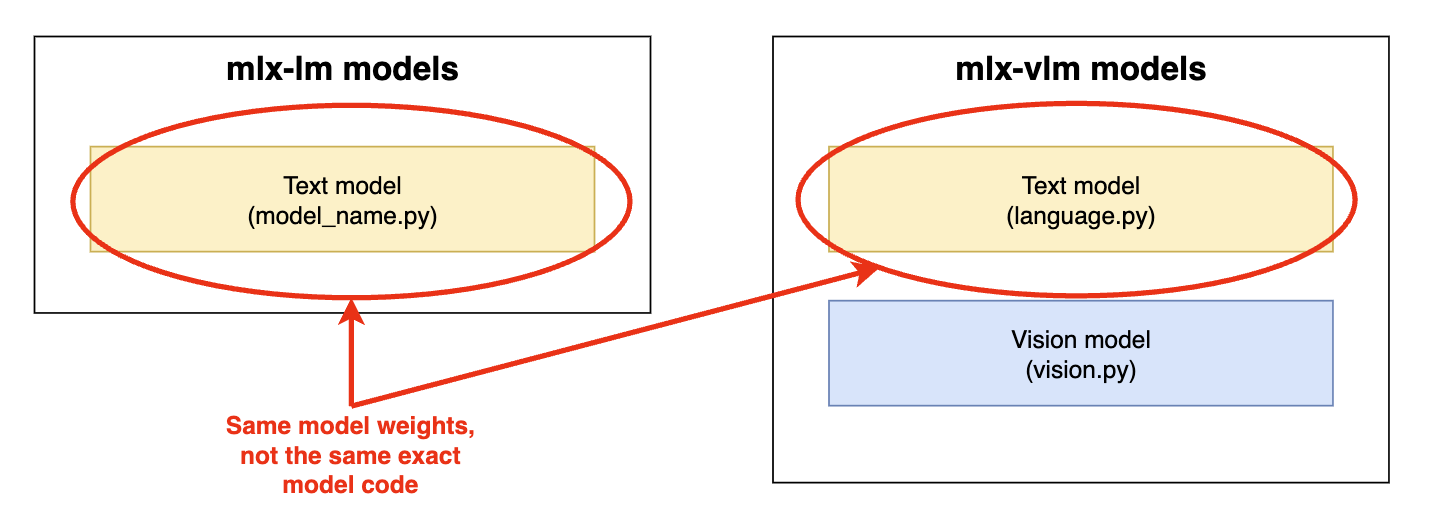
MLX 生态系统中的模型实现
在 MLX Python 生态中,有两个主要库提供模型实现以及与 Apple Silicon 上的 LLM 交互的基础设施
从历史上看,mlx-lm 包含了不具备多模态功能的纯文本模型实现,而 mlx-vlm 则是 MLX VLM 实现的实际承载地。
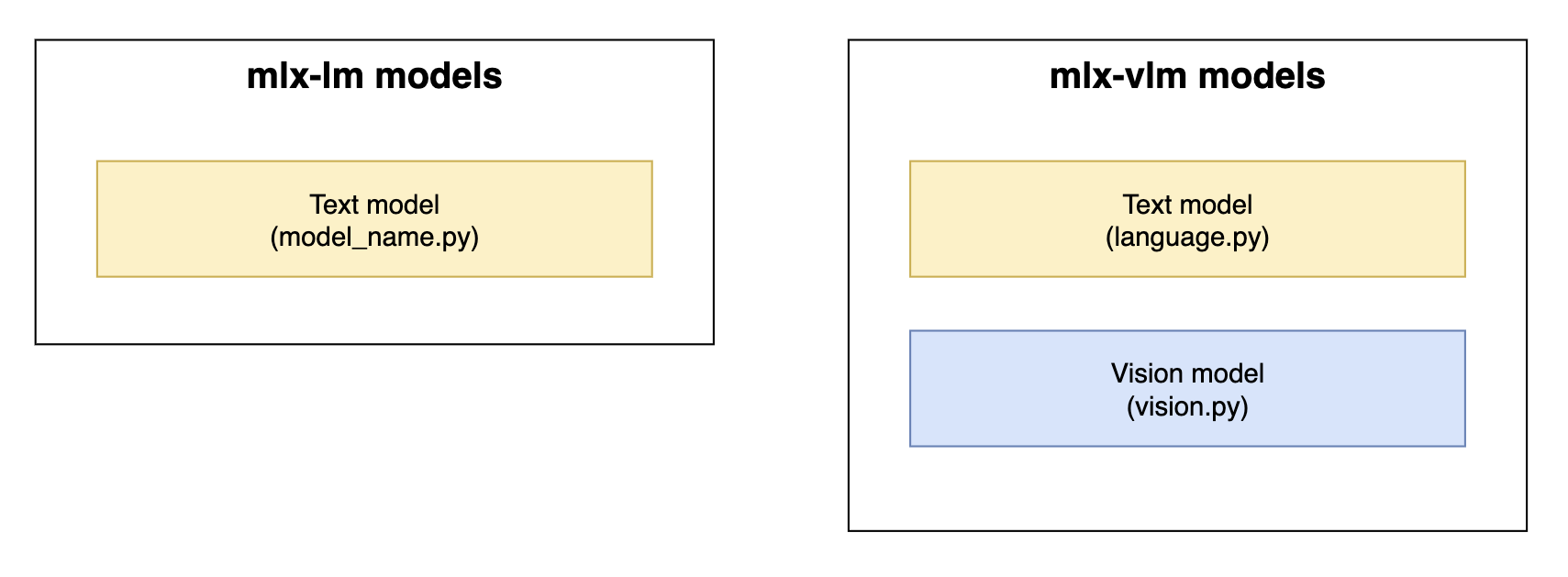
mlx-lm 和 mlx-vlm 中的模型实现组件。黄色 = 文本模型组件。蓝色 = 视觉模型组件
LM Studio 的 mlx-engine 最初是采用简单的“分叉”架构开发的,以支持纯文本模型和具备视觉能力的模型
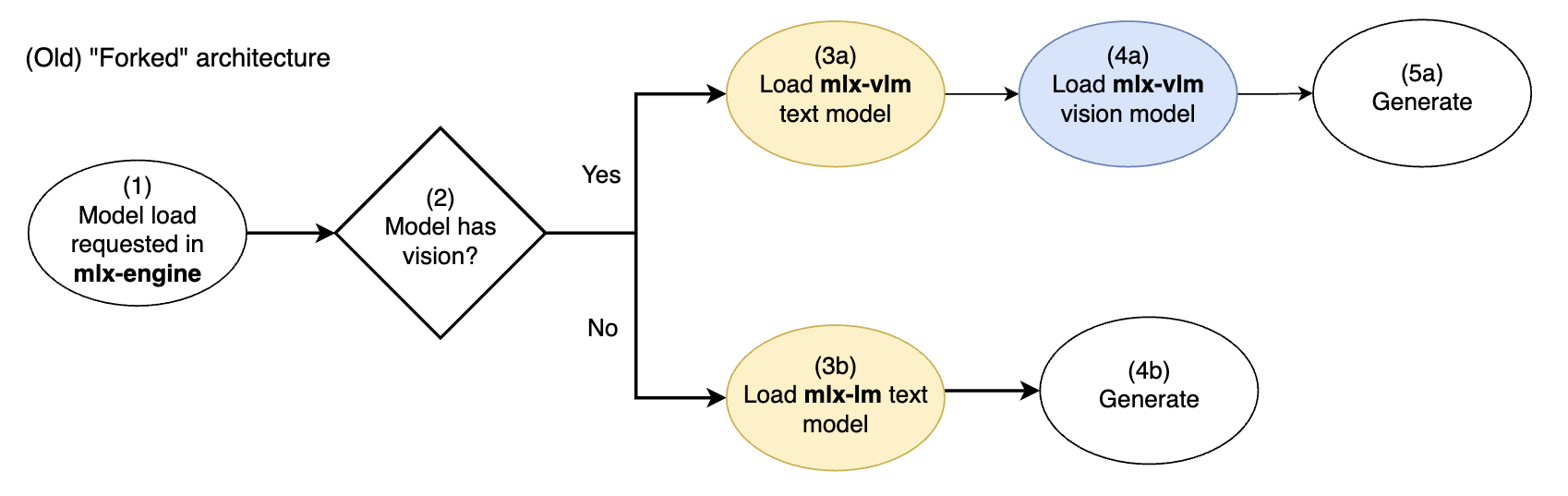
旧版 mlx-engine 的分叉视觉模型架构。黄色 = 文本模型组件。蓝色 = 视觉模型组件
如果模型具备视觉能力,则会专属使用 mlx-vlm 模型实现(文本 + 视觉)。如果模型是纯文本的,则会专属使用 mlx-lm 模型实现(文本)。
在每个路径中都使用了不同的文本模型实现(来自 mlx-lm 或 mlx-vlm)。
问题:分叉架构
mlx-engine 的这种朴素分叉架构存在以下问题
- 当
mlx-lm和mlx-vlm的功能并非完全对等或在行为上存在细微差异时,我们应该使用哪一个?- 我们如何限制多模态模型与纯文本模型交互体验的差异?
- 假设一个实现比另一个性能更好,或者一个包含另一个没有的 bug。我们如何一致地选择使用
mlx-lm还是mlx-vlm?我们是否应该根据请求在它们之间热切换加载(复杂)?
- 如果我们在这两者之间进行任何切换,或支持使用多模态模型的纯文本变体(例如,这个 Gemma 3 纯文本模型),那么给定模型的 bug 和维护范围将增加一倍。这是因为存在两个共存的实现,它们被有条件地用于推理相同的底层模型。因此,我们必须确保两个独立的模型都没有 bug,才能在 LM Studio 中提供无 bug 的体验。
同一个文本模型存在两个独立版本
我们的解决方案:两全其美
我们旨在结合 mlx-lm 和 mlx-vlm 的核心组件,为所有 MLX LLM 和 VLM 创建一个“统一的”(无分叉)推理引擎。
在与 @awni 和 @Blaizzy 进行宝贵讨论后,我们通过以下贡献实现了这一点
mlx-lm
mlx-vlm
新的 mlx-engine 统一视觉模型架构。mlx-lm 文本模型通过 mlx-vlm 视觉附加组件进行扩展
在此统一架构中,始终从 mlx-lm 加载多模态 LLM 的核心文本模型 (2),不再可能从 mlx-vlm 加载略有不同的文本模型。
然后我们有条件地加载一个 VisionAddOn,它使用 mlx-vlm 功能 (3,4) 从图像生成嵌入,这些嵌入可被 mlx-lm 文本模型理解(请参阅 mlx-engine 中的 Gemma3VisionAddOn 实现)。
通过这种设置,我们能够以精简且单一路径的方式推理多模态模型。这有助于我们发布更简洁、更易于维护且性能更佳的 LM Studio MLX 引擎。
Gemma 3 12B QAT,均在 M3 MacBook Pro 上使用 MLX 4 位。统一架构下,后续 TTFT 速度快约 25 倍
详情:mlx-engine 中的 VisionAddOns
LM Studio 新的 mlx-engine 统一架构的核心在于,它允许我们对所有多模态模型使用来自 mlx-lm 的文本模型实现,同时仍然能够利用 mlx-vlm 的视觉模型组件来生成可被文本模型理解的图像嵌入。
这是通过引入 VisionAddOns(源码)实现的,它们是可用于为多模态模型生成图像嵌入的模块化组件。这些 VisionAddOns 实现了由 BaseVisionAddOn 抽象类定义的通用接口,例如
class BaseVisionAddOn: """ Base class that defines the interface for a VisionAddOn. """ @abstractmethod def __init__(self): """ Where load of vision model components is intended to occur. """ @abstractmethod def compute_embeddings( self, text_model: nn.Module, prompt_tokens: mx.array, images_b64: List[str], ) → mx.array: """ Returns input embeddings for the language model after text/image merging of the prompt """
VisionAddOns 生成图像嵌入,这些嵌入可以作为新的 input_embeddings 参数输入到 mlx-lm 的 stream_generate() 函数中(请参阅 mlx-lm 中进行的提交)。
目前,Gemma 3(Gemma3VisionAddOn)和 Pixtral(PixtralVisionAddOn)是仅有的两个已迁移到统一架构的模型。然而,该架构的设计使得可以轻松地将更多 VisionAddOns 添加到 mlx-engine 的 vision_add_ons 目录中,然后 在此处接入 ModelKit
VISION_ADD_ON_MAP = { "gemma3": Gemma3VisionAddOn, "pixtral": PixtralVisionAddOn, }
非常欢迎为我们的开源仓库 https://github.com/lmstudio-ai/mlx-engine 贡献,以扩展此模式!例如,请参阅 mlx-engine issue 将 VisionAddOn 模式扩展到 Qwen2.5VL #167。
反馈与贡献
- 在我们的开源
mlx-engine仓库 https://github.com/lmstudio-ai/mlx-engine 查看和/或贡献 - 从 https://lm-studio.cn/download 下载最新版 LM Studio。
- 刚接触 LM Studio?前往文档:LM Studio 入门指南。
- 如需讨论和社区交流,请加入我们的 Discord 服务器:https://discord.gg/aPQfnNkxGC
- 如果您想在您的组织中使用 LM Studio,请联系我们:LM Studio 商业合作