文档
LM Studio 入门指南
LM Studio 入门指南
您可以在 LM Studio 中本地使用公开可用的大型语言模型 (LLM),例如 Llama 3.1、Phi-3 和 Gemma 2,利用您计算机的 CPU 以及可选的 GPU。
请检查您的计算机是否满足最低系统要求。
信息
您有时可能会看到诸如 open-source models 或 open-weights models 之类的术语。不同的模型可能在不同的许可和不同程度的“开放性”下发布。为了在本地运行模型,您需要能够访问其“权重”,这些权重通常以一个或多个以 .gguf、.safetensors 等结尾的文件形式分发。
快速入门
首先,安装最新版本的 LM Studio。您可以从这里获取。
完成设置后,您需要下载您的第一个 LLM。
1. 下载 LLM 到您的计算机
前往“发现”选项卡下载模型。选择一个精选选项,或通过搜索查询(例如 "Llama")搜索模型。有关下载模型的更多详细信息,请参阅此处。
LM Studio 中的“发现”选项卡
2. 将模型加载到内存
前往“聊天”选项卡,然后
- 打开模型加载器
- 选择您下载的(或侧载的)模型之一。
- (可选)选择加载配置参数。

在 macOS 上使用 cmd + L 或在 Windows/Linux 上使用 ctrl + L 快速打开模型加载器
加载模型是什么意思?
加载模型通常意味着分配内存,以便能够在计算机的 RAM 中容纳模型的权重和其他参数。
3. 聊天!
模型加载完成后,您就可以在“聊天”选项卡中开始与模型进行来回对话。
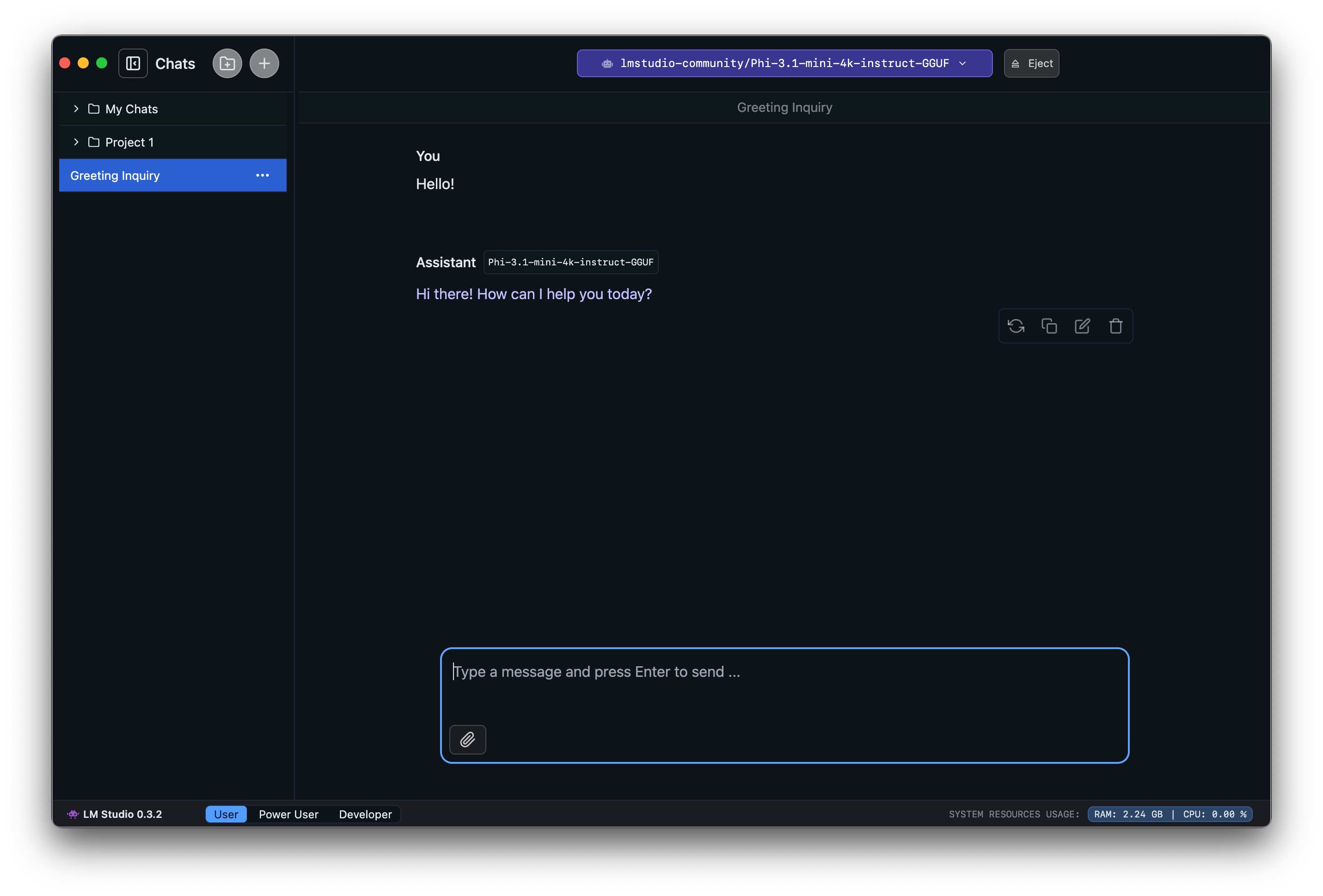
macOS 上的 LM Studio
社区
在 LM Studio Discord 服务器上与其他 LM Studio 用户聊天,讨论 LLM、硬件等。