LM Studio 0.3.9
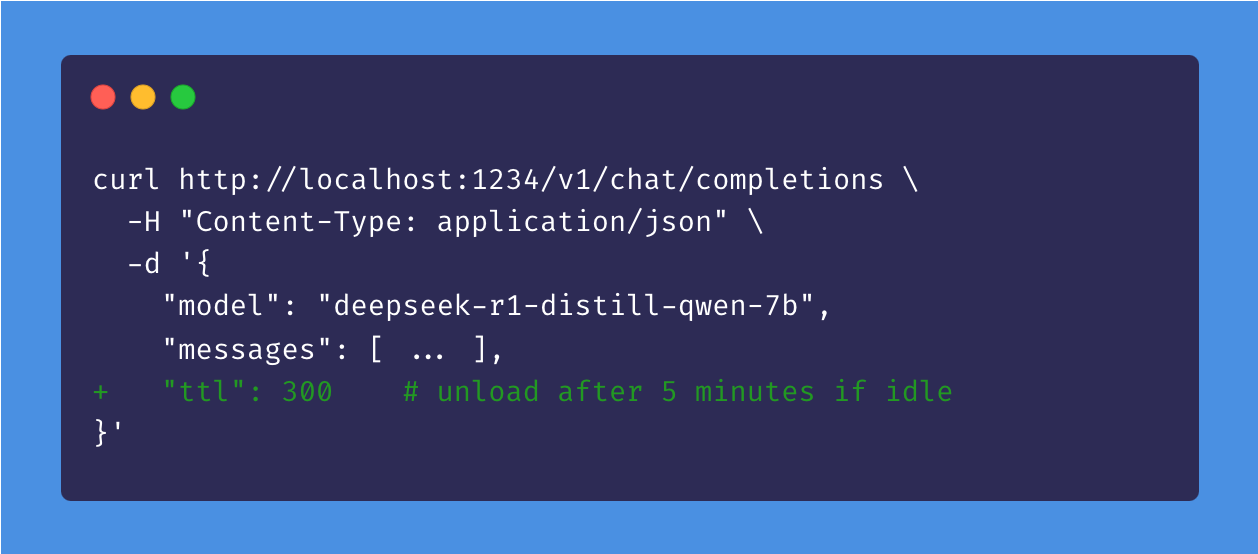
可选地在一定时间后自动卸载未使用的 API 模型
LM Studio 0.3.9 包含一个新功能:**空闲 TTL**,支持 Hugging Face 存储库中的嵌套文件夹,以及一个实验性 API,用于在聊天完成响应中以单独字段接收 reasoning_content。
0.3.9 的早期版本在 DeepSeek R1 聊天完成响应流式传输方面存在一个 bug。请更新到最新版本 (5) 以修复此问题。
通过应用内更新或从 https://lm-studio.cn/download 升级。
空闲 TTL 和自动驱逐
用例:想象您正在使用像 Zed、Cline 或 Continue.dev 这样的应用来与 LM Studio 提供的 LLM 进行交互。这些应用利用 JIT 在您首次使用模型时按需加载它们。
问题:当您不主动使用某个模型时,您可能不希望它一直加载在内存中。
解决方案:为通过 API 请求加载的模型设置一个 TTL(生存时间)。空闲计时器在模型每次收到请求时都会重置,因此在您使用它时它不会消失。如果模型没有执行任何工作,则被认为是空闲的。当空闲 TTL 到期时,模型会自动从内存中卸载。
您可以在请求负载中以秒为单位设置 TTL,或者在命令行中使用 lms load --ttl <seconds>。
在文档文章中阅读更多:TTL 和自动驱逐。
聊天完成响应中独立的 reasoning_content
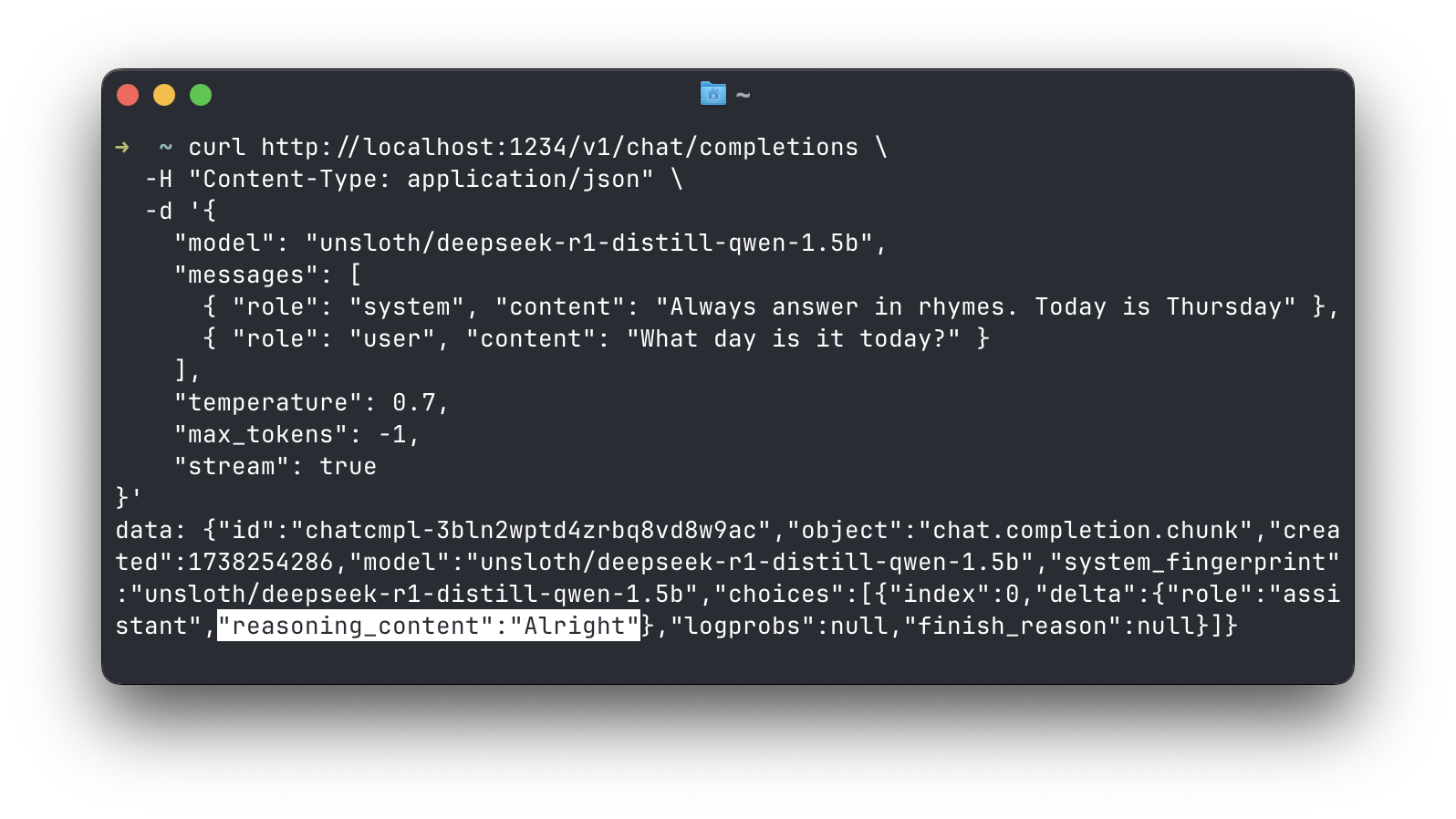
对于 DeepSeek R1,在单独的字段中获取推理内容
DeepSeek R1 模型在 <think> </think> 标签内生成内容。此内容是模型的“推理”过程。在聊天完成响应中,您现在可以按照 DeepSeek API 中的模式,在名为 reasoning_content 的单独字段中接收此内容。
这适用于流式和非流式完成。您可以在“应用设置”>“开发者”中开启此功能。此功能目前处于实验阶段。
注意:根据 DeepSeek 的文档,您不应在下一次请求中将推理内容传回给模型。
LM 运行时自动更新
LM Studio 支持多种 llama.cpp 引擎变体(仅限 CPU、CUDA、Vulkan、ROCm、Metal)以及 Apple MLX 引擎。这些引擎会频繁更新,尤其是在新模型发布时。
为了减少手动更新多个组件的需求,我们引入了运行时自动更新功能。此功能默认启用,但您可以在“应用设置”中将其关闭。
运行时更新后,您将看到显示发布说明的通知。您也可以在运行时选项卡中自行管理此功能:Windows/Linux 上为 Ctrl + Shift + R,macOS 上为 Cmd + Shift + R。

LM 运行时将自动更新到最新版本。您可以在设置中关闭此功能。
支持 Hugging Face 存储库中的嵌套文件夹
一项期待已久的功能:您现在可以从 Hugging Face 存储库的嵌套文件夹中下载模型。如果您喜欢的模型发布者将其模型组织在子文件夹中,您现在可以直接在 LM Studio 中下载它们。
这使得下载模型变得容易,例如 https://hugging-face.cn/unsloth/DeepSeek-R1-GGUF。对于 lms get <hugging face url> 也适用。
# Warning: this is a very large model lms get https://hugging-face.cn/unsloth/DeepSeek-R1-GGUF
0.3.9 - 完整更新日志
版本 6
- 修复了在包含图片的聊天中使用纯文本模型时出现“无法读取未定义属性”的问题
- 修复了 Windows 上导致某些机器上的 LM 运行时行为异常的路径解析问题
- 修复了 CUDA 模型加载崩溃问题,“llm_engine_cuda.node. 文件无法由系统访问”
- ROCm 模型生成乱码问题
- 修复了使用旧版本应用程序创建的聊天中 RAG 消息不显示的问题
- 修复了输入法编辑器 (IME) 错误:现在只有在输入完成时,按下 Enter 键才会发送消息
版本 5
- 修复了一个 API 错误,即在流式传输 DeepSeek R1 聊天完成响应时,
reasoning_content设置未生效
版本 4
- 新实验性 API:在聊天完成响应中(流式和非流式)在单独的字段中发送
reasoning_content- 适用于在
<think></think>标签内生成内容的模型(如 DeepSeek R1) - 在“应用设置”>“开发者”中开启
- 适用于在
版本 3
- 新增:在“聊天外观”中添加一个选项,用于自动展开新添加的“思考 UI”块
- 新增:当应用发出系统资源不足的错误通知时,显示快速访问防护栏配置
- 修复了一个错误,即如果非默认模型目录被删除,则新模型将不会被索引
- 修复了硬件检测中的一个错误,该错误在使用 Vulkan 后端时,有时会在多 GPU 设置中错误地过滤掉 GPU
- 修复了模型加载 UI 中的一个错误,即不带闪存注意力的 F32 缓存类型未被识别为 llama.cpp Metal 运行时的有效配置
版本 2
- 新增:添加了对从 Hugging Face 存储库的嵌套文件夹下载模型的支持
- 改进了直接使用 Hugging Face URL 进行搜索的支持
- 新增:自动更新所选运行时扩展包(您可以在“设置”中关闭此功能)
- 新增:添加了使用 LM Studio 的 Hugging Face 代理的选项。这可以帮助那些直接访问 Hugging Face 遇到困难的用户
- 新增:MLX 模型的 KV 缓存量化(需要 mlx-engine/0.3.0)
- “我的模型”选项卡更新:更整洁的模型名称,以及模型类型的侧边栏类别
- 可以在“应用设置”>“通用”中切换回显示完整文件名
- 要查看原始模型元数据(以前是:(i) 按钮),请右键单击模型名称并选择“查看原始元数据”
- 修复了在“采样设置”中清除 Top K 会触发错误的问题
版本 1
- 新增:TTL - 可选地在一定时间后自动卸载未使用的 API 模型(请求负载中的
ttl字段)- 命令行使用:
lms load --ttl <seconds> - API 参考:https://lm-studio.cn/docs/api/ttl-and-auto-evict
- 命令行使用:
- 新增:自动驱逐 - 可选地在加载新模型之前自动卸载先前加载的 API 模型(在“应用设置”中控制)
- 修复了模型思考块内的公式有时会在块下方生成空白区域的错误
- 修复了 Toast 通知中的文本无法滚动的情况
- 修复了取消选中并重新选中“结构化输出 JSON”会导致 schema 值消失的错误
- 修复了生成时自动滚动有时不允许向上滚动的问题
- [开发者] 将日志记录选项移至“开发者日志”面板标题 (••• 菜单)
- 修复了“聊天外观”字体大小选项无法缩放“思考”块中文本的问题
更多
- 下载适用于 macOS、Windows 或 Linux 的最新 LM Studio 应用程序。
- 如果您想在工作场所的组织中使用 LM Studio,请联系我们:LM Studio 商务版
- 如需讨论和社区支持,请加入我们的 Discord 服务器。
- LM Studio 新手?请前往文档:文档:LM Studio 入门。