文档
API
空闲 TTL 和自动清除
API
空闲 TTL 和自动清除
可选地在一定时间后自动卸载空闲模型 (TTL)
LM Studio 0.3.9 (b1) 引入了为 API 模型设置**存活时间 (TTL)** 的功能,并可选择在加载新模型之前自动驱逐以前加载的模型。
这些功能补充了 LM Studio 的按需模型加载 (JIT),以自动化高效内存管理并减少手动干预的需要。
背景
-
JIT 加载使得在其他应用程序中使用 LM Studio 模型变得容易:您无需先手动加载模型即可使用它。然而,这也意味着模型即使在不使用时也可能保留在内存中。[默认:启用] -
(新)
空闲 TTL(技术上是:存活时间)定义了模型在没有收到任何请求的情况下可以在内存中停留多长时间。当 TTL 到期时,模型会自动从内存中卸载。您可以使用请求有效负载中的ttl字段设置 TTL。[默认:60 分钟] -
(新)
自动驱逐是一项功能,它在加载新模型之前卸载以前 JIT 加载的模型。这使得客户端应用程序可以在模型之间轻松切换,而无需先手动卸载它们。您可以在“开发人员”选项卡 >“服务器设置”中启用或禁用此功能。[默认:启用]
空闲 TTL
用例:想象您正在使用像Zed、Cline或Continue.dev这样的应用程序与 LM Studio 提供的 LLM 进行交互。这些应用程序利用 JIT 在您首次使用模型时按需加载模型。
问题:当您不主动使用某个模型时,您可能不希望它一直加载在内存中。
解决方案:为通过 API 请求加载的模型设置 TTL。每次模型收到请求时,空闲计时器都会重置,因此在您使用它时它不会消失。如果模型没有执行任何工作,则被认为是空闲的。当空闲 TTL 到期时,模型会自动从内存中卸载。
设置应用程序默认空闲 TTL
默认情况下,JIT 加载的模型具有 60 分钟的 TTL。您可以像这样为任何通过 JIT 加载的模型配置默认 TTL 值
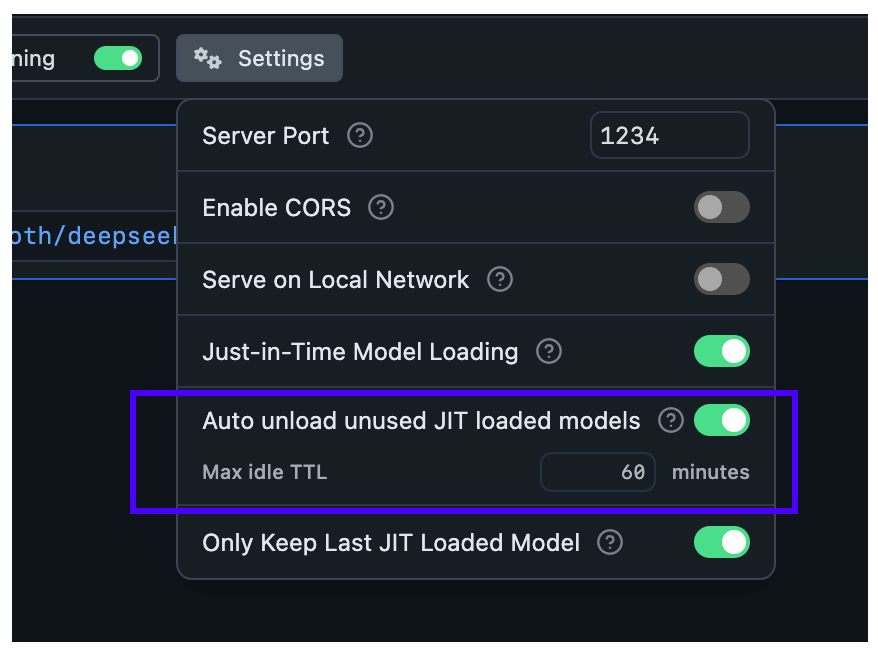
设置默认 TTL 值。将用于所有 JIT 加载的模型,除非在请求有效负载中另有指定
在 API 请求中设置每个模型的 TTL 模型
当启用 JIT 加载时,对模型的**第一个请求**会将其加载到内存中。您可以在请求有效负载中为该模型指定 TTL。
这适用于针对OpenAI 兼容 API和LM Studio 的 REST API的请求
curl https://:1234/api/v0/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1-distill-qwen-7b", + "ttl": 300, "messages": [ ... ] }'
如果此模型是 JIT 加载的,它将设置 5 分钟(300 秒)的 TTL。
使用lms加载模型的 TTL 设置
默认情况下,使用lms load加载的模型没有 TTL,并且会保留在内存中,直到您手动卸载它们。
您可以像这样为使用lms加载的模型设置 TTL
lms load <model> --ttl 3600
加载一个 TTL 为 1 小时(3600 秒)的<model>
在服务器选项卡中加载模型时指定 TTL
您也可以在服务器选项卡中加载模型时设置 TTL,如下所示
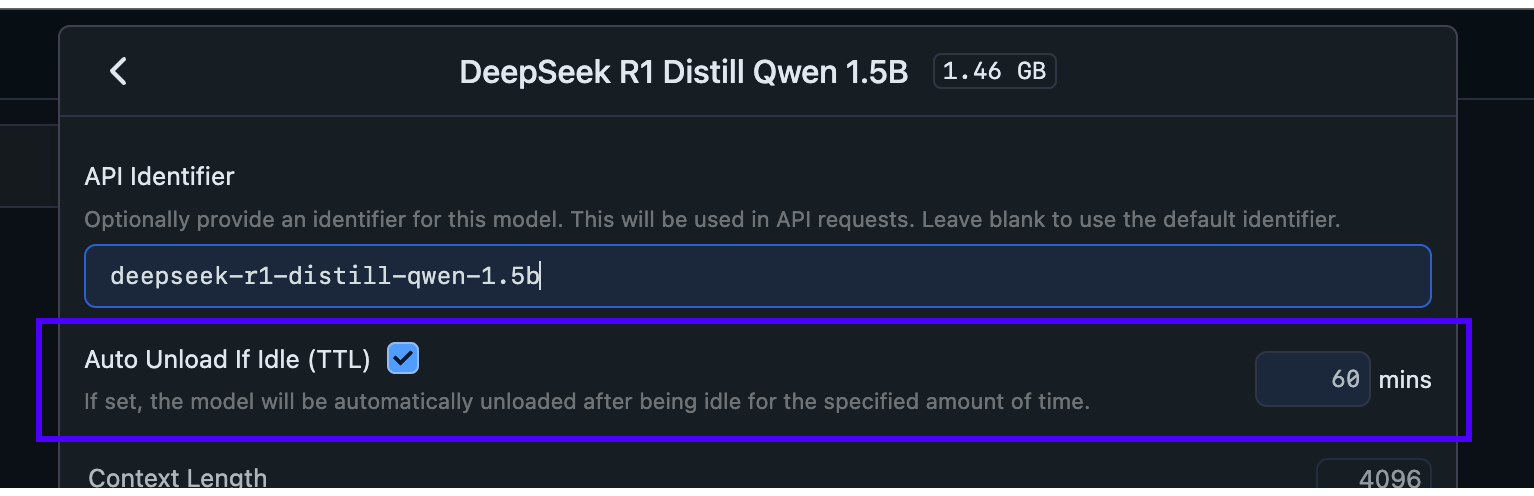
在服务器选项卡中加载模型时设置 TTL 值
配置 JIT 加载模型的自动驱逐
通过此设置,您可以确保通过 JIT 加载的新模型首先自动卸载以前加载的模型。
当您想要从其他应用程序切换模型而无需担心内存中累积未使用的模型时,此功能很有用。
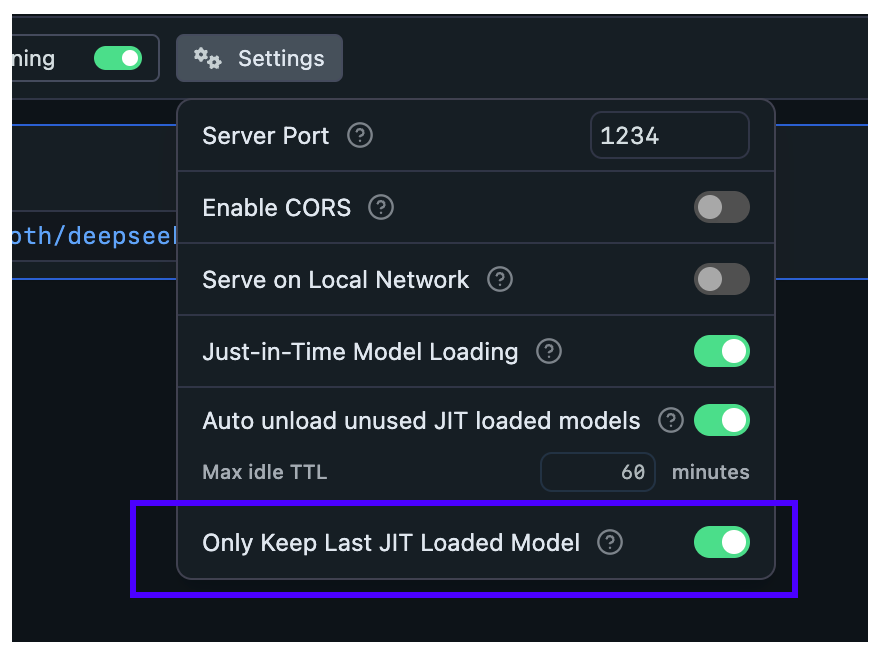
在“开发人员”选项卡 >“服务器设置”中为 JIT 加载的模型启用或禁用自动驱逐
当自动驱逐开启时(默认)
- 每次在内存中最多保留
1个模型(通过 JIT 加载时) - 非 JIT 加载的模型不受影响
当自动驱逐关闭时:
- 从外部应用程序切换模型将使以前的模型保留在内存中
- 模型将保持加载状态,直到
- 它们的 TTL 到期
- 您手动卸载它们
此功能与 TTL 协同工作,为您的工作流提供更好的内存管理。
术语
TTL:存活时间,是一个从网络协议和缓存系统借用的术语。它定义了资源在被视为过期并被驱逐之前可以保持分配状态的时间。
此页面的源文件可在GitHub上找到
本页内容
背景
空闲 TTL
设置应用程序默认空闲 TTL
在 API 请求中设置每个模型的 TTL 模型
使用 lms 加载模型的 TTL 设置
在服务器选项卡中加载模型时指定 TTL
配置 JIT 加载模型的自动驱逐
术语