LM Studio 0.3.5
LM Studio 0.3.5 引入了无头模式、按需模型加载,并更新了 mlx-engine 以支持 Pixtral(MistralAI 的支持视觉的 LLM)。
👾 我们正在纽约招聘一名 TypeScript SDK 工程师,以构建用于设备端 AI 的应用和 SDK。
获取最新的 LM Studio
LM Studio 作为您的本地 LLM 后台服务器
在此版本中,我们添加了一系列面向开发人员的功能,旨在使 LM Studio 作为您的后台 LLM 提供商更加符合人体工程学。我们实现了无头模式、按需模型加载、服务器自动启动,以及一个新的 CLI 命令,用于从终端下载模型。这些功能对于支持本地 Web 应用程序、代码编辑器或 Web 浏览器扩展等非常有用。
无头模式
通常,要使用 LM Studio 的功能,您必须保持应用程序打开。考虑到 LM Studio 的图形用户界面,这听起来很明显。但对于某些开发人员工作流程,主要是那些专门使用 LM Studio 作为服务器的工作流程,保持应用程序运行会导致不必要的资源消耗,例如视频内存。此外,在重新启动后记住启动应用程序并手动启用服务器也很麻烦。现在不会了!进入:无头模式 👻。
无头模式,或“本地 LLM 服务”,使您能够利用 LM Studio 的技术(补全、聊天补全、嵌入、通过 llama.cpp 或 Apple MLX 实现结构化输出)作为本地服务器为您的应用程序提供动力。
一旦您打开“启用本地 LLM 服务”,LM Studio 的进程将在机器启动时在没有 GUI 的情况下运行。
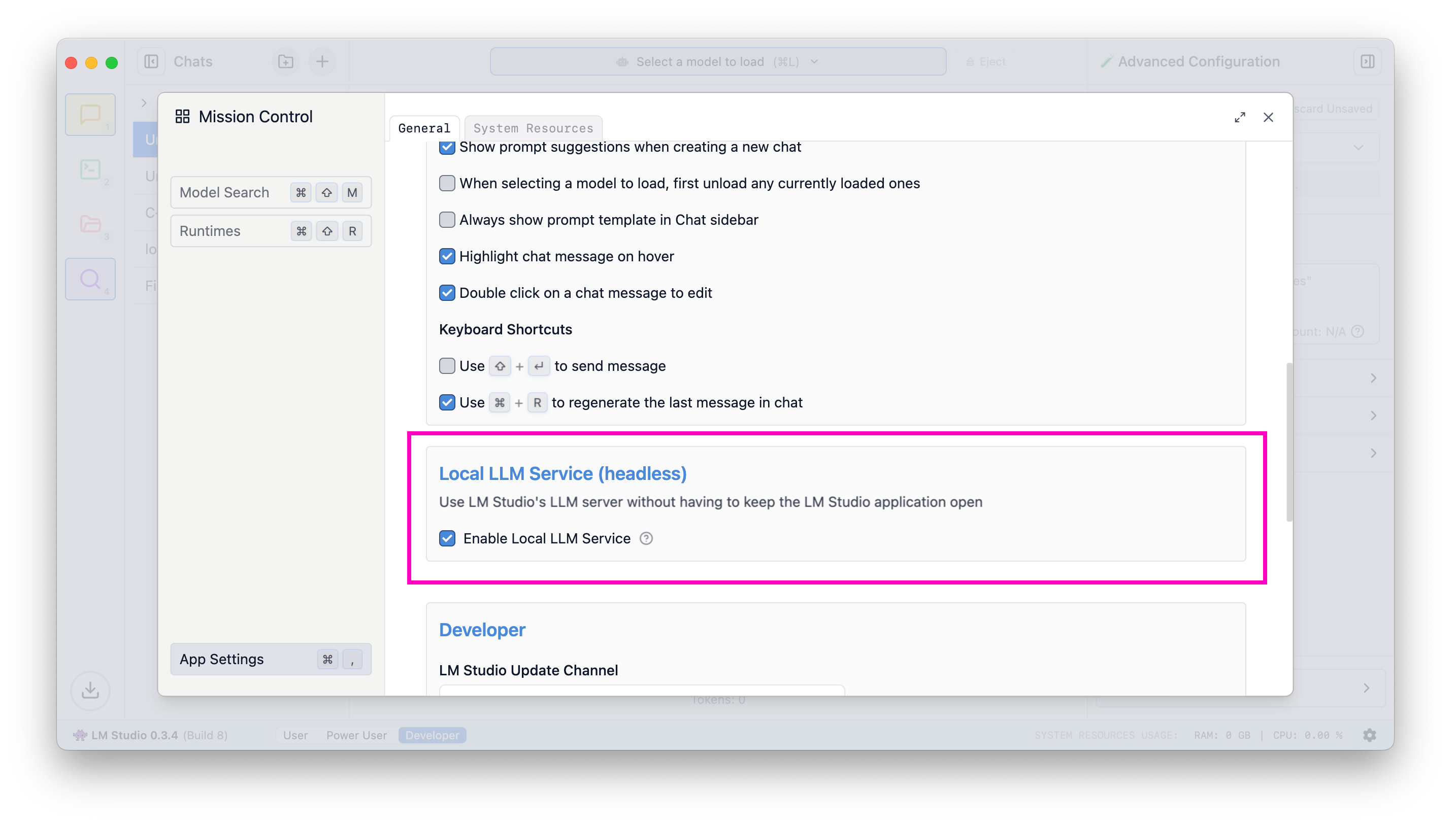
启用 LLM 服务器在机器登录时启动
最小化到托盘
要将 LM Studio 切换到后台运行,您可以将其最小化到系统托盘。这将隐藏 Dock 图标并释放图形用户界面占用的资源。
在 Windows 上最小化到托盘
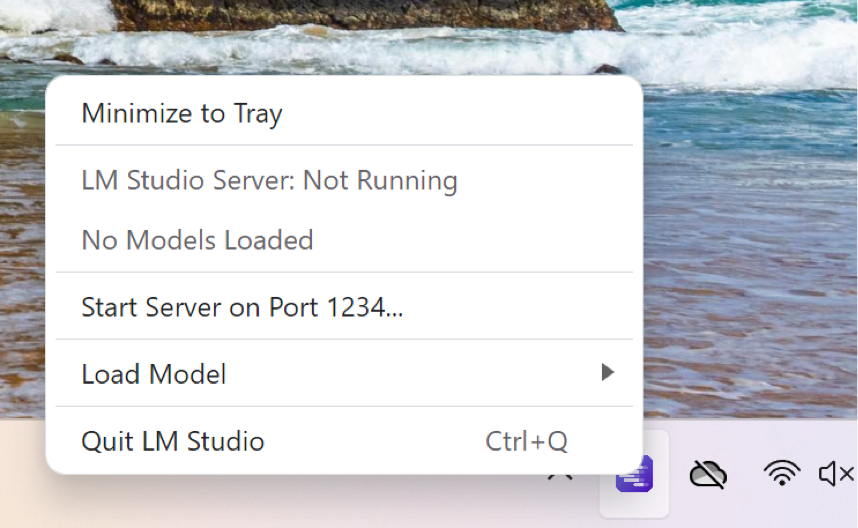
在 Windows 上将 LM Studio 发送到后台运行
在 Mac 上最小化到托盘
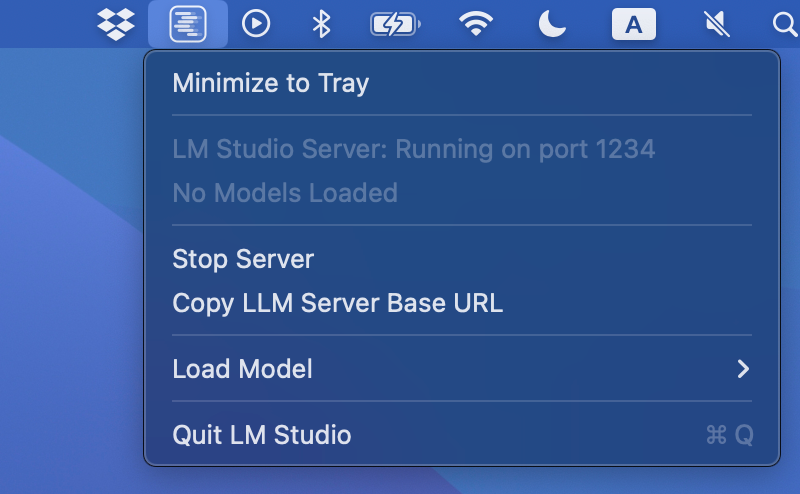
在 macOS 上将 LM Studio 发送到后台运行
记住上次服务器状态
如果开启服务器,下次应用程序启动时(无论是您启动,还是在服务模式下启动),它都会自动启动。关闭服务器也是如此。
要确保服务器已开启,请运行以下命令
# Start the server lms server start
相反,要确保服务器已关闭,请运行
# Stop the server lms server stop
按需模型加载
0.3.5 版本之前:如果您想通过 LM Studio 使用某个模型,您必须首先自行加载它:通过用户界面或通过 lms load(或通过 lmstudio-js)。
0.3.5 版本之后:要使用某个模型,只需向其发送推理请求。如果模型尚未加载,它将在您的请求返回之前加载。这意味着第一个请求可能需要几秒钟才能完成加载操作,但后续调用应该像往常一样快速。
将按需加载与每个模型设置结合使用
使用按需模型加载,您可能会想如何配置加载设置,例如上下文长度、GPU 卸载百分比、Flash Attention 等。这可以通过 LM Studio 的 每个模型的默认设置 功能解决。
通过每个模型设置,您可以预先确定软件在加载给定模型时默认使用的加载参数。
🛠️ API 变更: GET /v1/models 行为
没有 JIT 加载(0.3.5 之前的默认值):仅返回已加载到内存中的模型
有 JIT 加载:返回所有可加载的本地模型
如何开启 JIT 模型加载
如果您之前使用过 LM Studio,请在“开发者”选项卡中翻转此开关以开启即时模型加载。新安装的默认开启此功能。
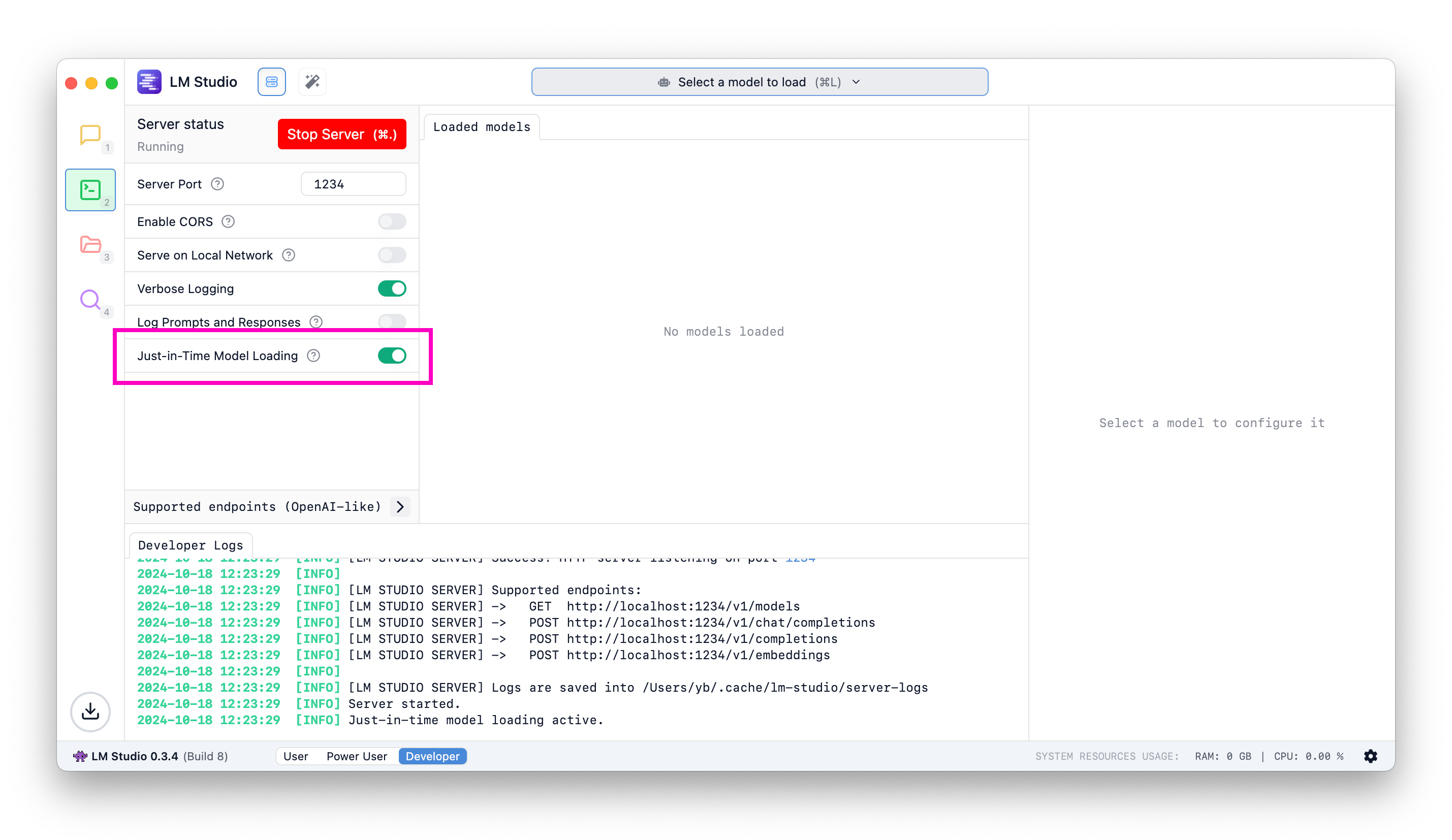
按需加载模型
lms get
LM Studio 的 CLI lms 获得了一个新命令,让您可以直接从终端下载模型。
当您安装新版本的 LM Studio 时,lms 会自动更新。
下载模型:lms get {author}/{repo}
要下载 Meta 的 Llama 3.2 1B,请运行
lms get bartowski/llama-3.2-1b-instruct-gguf
下载特定量化
我们引入以下表示量化的符号:@{quantization}
获取 q4_k_m 量化
lms get lmstudio-community/llama-3.2-1b-instruct-gguf@q4_k_m
获取 q8_0 量化
lms get lmstudio-community/llama-3.2-1b-instruct-gguf@q8_0
提供显式的 huggingface.co URL
您可以提供明确的 Hugging Face URL 来下载特定模型
lms get https://hugging-face.cn/lmstudio-community/granite-3.0-2b-instruct-GGUF
量化符号在这里也适用!
lms get https://hugging-face.cn/lmstudio-community/granite-3.0-2b-instruct-GGUF@q8_0
这将下载此模型的 q8_0 量化版本。
通过 Apple MLX 支持 Pixtral
在 LM Studio 0.3.4 中,我们引入了对 Apple MLX 的支持。请在此处阅读相关内容。在 0.3.5 中,我们更新了底层的 MLX 引擎(它是开源的),并添加了对 MistralAI 的 Pixtral 的支持!
这得益于采用了 Blaizzy/mlx-vlm 版本 0.0.15。
您可以通过模型搜索 (⌘ + ⇧ + M) 下载 Pixtral,或者像这样使用 lms get
lms get mlx-community/pixtral-12b-4bit
如果您的 Mac 内存超过 16GB,最好是 32GB 以上,请尝试使用它。
错误修复
- [Bug fix] 修复 RAG 在后续提示中将文档重新注入上下文的问题
- 修复了 RAG 不工作的问题 (https://github.com/lmstudio-ai/mlx-engine/issues/4)
- 修复了任务控制周围的轮廓闪烁问题
- [Mac][MLX 引擎] 修复了侧载量化 MLX 模型的问题 (https://github.com/lmstudio-ai/mlx-engine/issues/10)
LM Studio 0.3.5 - 完整更新日志
- 将 LM Studio 作为服务运行(无头模式)
lms load、lms server start不再需要启动 GUI- 能够随机器启动而运行
- 服务器启动/停止按钮将记住上次设置
- 当 LM Studio 作为服务运行时,这很有用。
- 模型搜索改进
- Hugging Face 搜索现在自动进行,无需 Cmd / Ctrl + Enter
- OpenAI 端点的即时模型加载
- 切换任务控制全屏/模态模式的按钮
- 更新了基于 llama.cpp 的 JSON 响应生成;现在支持更复杂的 JSON 模式
- 托盘菜单选项,用于最小化应用程序到托盘,复制服务器基本 URL
- 在 Linux 上入门期间勾选框以将
lms添加到 PATH - [Mac][MLX Vision] 将 mlx-vlm 版本升级到
0.0.15,支持 Qwen2VL - [Mac][MLX 引擎] Transformers 更新至
4.45.0 - [UI] 将聊天外观控制移至顶部栏
- [UI] 调整了每条消息操作按钮的大小
- 本地化
- 感谢 Goekdeniz-Guelmez 改进了德语翻译
- 感谢 dwirx 提供的印尼语翻译
更多
- 下载适用于 macOS、Windows 或 Linux 的最新 LM Studio 应用程序。
- LM Studio 新用户?请访问文档:文档:LM Studio 入门。
- 如需讨论和社区支持,请加入我们的 Discord 服务器。
- 如果您想在工作场所使用 LM Studio,请联系我们:LM Studio @ Work